논문출처 : e-hir.org/journal/view.php?number=1011
Prediction of Chronic Disease-Related Inpatient Prolonged Length of Stay Using Machine Learning Algorithms
1. Study Design Prediction models were constructed using an administrative claim dataset provided by a network of nine hospitals geographically localized within three adjacent counties in the Tampa Bay region, Florida, USA. The types of hospitals in the st
e-hir.org
연구 목표 : 5가지 다른 만성 질환(AMI, CHF, COPD, DB, PN)으로 진단 받은 입원 환자의 장기 입원 기간의 예측을 위한 지도학습모델을 비교
연구 대상 : 미국 플로리다 주 템파베이 지역에 인접한 9개의 병원에서 제공하는 질병 집단에 속하는 52,159명의 입원환자
- 병원 유형 : 일반병원, 교육병원, 전문병원
- 기간 : 2008.1 - 2012.7
- 집단 구성 : AMI 10,983명, CHF 9,194명, COPD 7,189명, DB 3,476명, PN 21,317명
사용 모델 : ANN, Decison tree C5.0, LSVM, KNN, Random forest
feature 추출 : 퇴원 청구에 대한 이전 연구 기반으로 입원 환자 진단 및 수익 코드에서 82개 공통특징과 몇 가지 질병 관련 특징 (진단 코드는 ICD-9 numeric, E 및 V 코드 사용해 추출)
결과 값 : LOS > 7은 장기로 봄 ( 전체 연구 모집단에서 임계 값을 백분위수에서 85번쨰로 두어 계산하여 정의)
모델링 프레임 워크
1. 데이터 전처리
- 결측치에 대해 15%이상 누락되었을 시 제외, 15%미만은 평균 혹은 중앙값으로 대체
- O-SVM으로 유사한 비율의 이상(1.92% - 2.44%)을 식별하여 데이터 세트에서 제외함
(O-SVM은 잡음이 있는 관측치에서 특이치 식별 가능)
- 유의 수준이 0.05인 feature에 대해 피어슨 상관 및 카이-제곱 검정을 사용하여 상관 관계가 있는 쌍 중에서 가장 높은 분산 인플레이션 계수를 가진 feature 삭제
2. 모델 교육
- 훈련 데이터 70%, 테스트 데이터 30%로 분리
- 중요 변수 식별 (feature importance랑 유사해 보임)
- 카이 제곱 필터링 (0.05 유의 수준에서 선택)
- SVM 기반 래퍼 알고리즘 (최대 200회 반복)
- SMOTE 사용하여 데이터 불균형 문제 해결(훈련 데이터를 오버 샘플링)
※ 여기서 불균형 데이터를 새로운 균형 데이터로 생성한 것은 불균형 데이터로 훈련할 때 알고리즘은 소수 클래스보다 다수 클래스에서 더 많이 학습하는 경향이 있어 예측 가능성이 제한되기 때문
- 각 방식별로 식별된 feature를 선택한 후 SMOTE 사용 여부로 구분된 데이터를 C5.0, LSVM, KNN, RF, ANN 모델을 교육(총 20가지 모델이 나옴, 데이터셋 4개 모델 5개여서)
3. 모델 평가
- AUC는 불균형의 영향을 받지 않아 사용 (단, 성능 저하를 감추는 경향이 있음)
- 불균형의 편향 최소화를 위해 민감도와 특이도도 고려
결과
- KNN은 다른 알고리즘보다 성능이 낮다.
- LSVM은 AUC 기준에서 모든 집단에서 다른 알고리즘보다 우수하다.
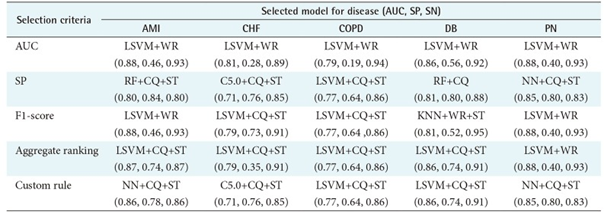
- AUC, 민감도, F1-score 등을 고려하여 어떤 데이터셋을 이용한 모델이 가장 좋은 지 나타내면 아래와 같다.
2. 주요 feature에 대한 결과
- 질병 심각도 지수(DB 집단은 제외), 동반 질환의 존재가 장기 LOS 예측의 주요 feature
- AMI, CHF 집단은 더 오래 머무는 경향
- 환자 상태를 평가하는 데 필요한 검사 횟수, 입학처, 지불자 등급도 LOS 연장과 관련이 있다.
- 환자 상태를 평가하는 데 필요한 검사 횟수는 AMI를 예상하는 장기 입원 환자와 관련 높다.
(검사 횟수가 많을수록 LOS가 연장될 위험이 커짐)
- 비상업적 지불자가 있는 PN 환자와 응급실을 통해 입원한 COPD 환자는 LOS 연장될 가능성 큼
한계 및 기존 연구와 비교
- 장기간의 LOS가 대부분의 만성 질환에서 혈액 형성 및 피부 질환 관련 동반 질환과 관련 있다는 이전의 여러 연구 뒷받침
- 일부 환자의 인구 통계, 성별 및 병원 위치가 장기간 LOS의 위험을 식별하는 데 기여했다고 보는 연구도 있지만 이전 연구에서 단일 병원 또는 특정 유형의 수술로 구성된 동종 데이터를 주로 사용했기에 불일치하는 것이다.
- 일반화 가능성을 제한할 수 있는 추가 연구의 필요하다. (왜 그런지 모르겠다.)
데이터 불균형 처리 방법 출처 : mkjjo.github.io/python/2019/01/04/smote_duplicate.html
[Python] SMOTE를 통한 데이터 불균형 처리
* 본 포스트는 개인연구/학습 기록 용도로 작성되고 있습니다. 데이터 분석시 쉽게 마주하게 되는 문제 중 하나가 데이터의 불균형이다. 우리가 찾고자하는 데이터의 타겟의 수가 매우 극소수인
mkjjo.github.io
데이터 불균형 처리 방법
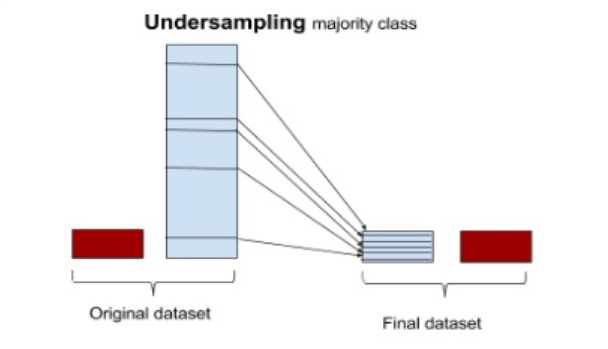
언더 샘플링
- 무작위 추출 : 무작위로 장상 데이터를 일부만 선택
- 유의정보 : 유의한 데이터만을 남기는 방식(알고리즘 : EasyEnsemble, BalanceCascade)
- 언더샘플링의 경우 데이터의 소실이 매우 크고, 떄로는 중요한 정상데이터를 잃게 될 수 있다.
※정상데이터 : 이상데이터(오류, 가짜데이터, 예외, 노이즈, 새로운 패턴 등의 데이터)가 아닌것
오버샘플링
- 무작위추출 : 무작위로 소수 데이터를 복제
- 유의정보 : 사전에 기준을 정해서 소수 데이터를 복제
- 정보가 손실되지 않는다는 장점이 있으나, 복제된 관측치를 원래 데이터 세트에 추가하기 만하면 여러 유형의 관측치를 다수 추가하여 overfitting을 초래할 수 있음 -> trainset의 성능은 좋으나 testset의 성능이 나빠질 수 있음

합성데이터 생성 : 소수 데이터를 단순 복제하는 것이 아니라 새로운 복제본을 만들어 내는 것
비용 민감 학습(Cost Sensitive Learning, CSL)
- 오분류하는 행위를 비용으로 측정
- Total Cost = C(FN) x FN + C(FP) x FP
(FN은 잘못 예측된 긍정적인 관찰의 수, FP는 잘못 예측된 부정적 사례 수 / C(FN)과 C(FP)는 False Negative 및 False Positive와 관련된 비용과 일치한다. C(FN) > C(FP))
- 잘못 분류된 비용을 설명하는 비용 매트릭스를 사용하여 불균형 학습 문제를 해결
SMOTE(Synthetic Minority Over-sampling Technique)
출처 : https://mkjjo.github.io/python/2019/01/04/smote_duplicate.html
[Python] SMOTE를 통한 데이터 불균형 처리
* 본 포스트는 개인연구/학습 기록 용도로 작성되고 있습니다. 데이터 분석시 쉽게 마주하게 되는 문제 중 하나가 데이터의 불균형이다. 우리가 찾고자하는 데이터의 타겟의 수가 매우 극소수인
mkjjo.github.io
- 부트스트래핑이나 KNN 모델 기법을 활용
1. 소수 데이터 중 특정 벡터(샘플)와 가장 가까운 이웃 사이의 차이를 계산
2. 이 차이에 0과 1사이의 난수를 곱한다.
3. 타겟 벡터에 추가한다.
4. 두 개의 특정 기능 사이의 선분을 따라 임의의 점을 선택할 수 있다.
- from imblearn.ver_sampling import SMOTE로 불러와서 사용 가능하다.

- 장점 : random하게 oversampling하는 것보다 overfitting이 일어날 가능성이 줄어들고 정보가 손실될 우려가 없다.
- 단점 : minor class(dataset 내에서 상대적으로 다수를 차지하는 않는 class)의 synthetic data(합성데이터)를 생성하는 동안 인접해있는 major class(dataset 내에서 상대적으로 다수를 차지하는 class)의 instance들의 위치는 고려하지 않는다. 그래서 클래스가 겹치거나 노이즈를 만들 수 있다. 즉, 고차원 데이터에 효율적이지 않다.
MSOTE(Modified synthetic minority oversampling technique)
출처 : www.analyticsvidhya.com/blog/2017/03/imbalanced-data-classification/
Class Imbalance | Handling Imbalanced Data Using Python
Class Imbalance is a very common problem in machine learning. This article lists ways to dealing with imbalanced classes in machine learning using Python.
www.analyticsvidhya.com
- SMOTE에서 약간 변형된 모델로 SMOTE는 데이터 세트에서 소수 클래스의 기본 분포와 잠재 소음을 고려하지 않는 부분을 수정했다.
- 소수 클래스의 샘플을 security/safe samples, border samples, latent noise sample로 총 3가지의 샘플로 나눈후 샘플간의 거리를 계산하여 수행한다.
- security/safe sample은 분류기의 성능을 향상시킬 수있는 요소이다.
- 노이즈는 분류기의 성능을 저하시킬 수 있는 데이터 포인트 요소이다.
- border sample은 노이즈 혹은 security로 분류하기 어려운 것이 분륜된다.
- security sample에 대해 k개의 가장 가까운 이웃에서 데이터 포인트를 무작위로 선택하고 border sample에서 가장 가까운 이웃을 선택하며 latent noise sample에 대해서는 아무것도 하지 않는다.
PS. 부트스트래핑
부트스트래핑이란 무엇입니까? - Minitab
표본 분포는 모집단의 랜덤 표본에서 가능한 통계 값을 얻을 수 있는 우도를 설명합니다 즉, 해당 크기의 모든 랜덤 표본 비율이 해당 값을 제공합니다. 부트스트래핑은 단일 랜덤 표본에서 복
support.minitab.com
표본 분포는 모집단의 랜덤 표본에서 가능한 통계 값을 얻을 수 있는 우도(=가능도)를 설명
*우도는 확률 분포의 모수가 어떤 확률변수의 표집값과 일관되는 정도를 나타내는 값
민감도, 특이도 출처 : blog.naver.com/PostView.nhn?blogId=win0k&logNo=221599042773&redirect=Dlog&widgetTypeCall=true&directAccess=false
모델 평가도 (특이도, 정확도, 민감도, 정밀도, 재현율) 정의
모델 평가도에서는 특이도, 정확도, 민감도, 정밀도, 재현율이 있으며 그 중에서도 특이도와 민감도는 RO...
blog.naver.com
민감도(Sensitivity), 특이도(Specificity)

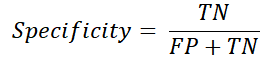
* sensitivity는 recall과 같은 수식이고 specificityaks precision이나 recall과 다르다.
유의수준
출처 : ko.wikipedia.org/wiki/%EC%9C%A0%EC%9D%98_%EC%88%98%EC%A4%80
유의 수준 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전.
ko.wikipedia.org
통계적인 가설검정에서 사용되는 기준값으로 일반적으로 유의 수준 α로 표시하고 95%의 신뢰도를 기준으로 한다면 0.05값이 유의수준 값이 된다. 가설검정의 절차에서 유의수준 값과 유의확률 값을 비교하여 통계적 유의성을 검정하게 된다.
O-SVM
[ML] 하나의 class만 학습시켜서 불균형 데이터 예측하기
Binary classification을 할 때 class의 데이터가 매우 불균형하거나 class에 한 개의 데이터만 있고 나머지 데이터가 없는 경우들이 있습니다. 이런 경우는 하나의 class만 학습시켜서 분류를 할 수 있는
ssung-22.tistory.com
- One-class SVM의 줄임말로 SVM과 달리 비지도 학습이다. 주어진 데이터를 잘 설명할 수 있는 최적의 support vector를 구하고 이 영역 밖의 데이터들은 outlier로 간주하는 방식으로 이상치 탐지, 이미지 검색, 문서/텍스트 분류 등에 사용된다.
- sklearn.svm.OneClassSVM으로 구현되어 있다.
매개 변수 관련 참고 : scikit-learn.org/stable/modules/generated/sklearn.svm.OneClassSVM.html
sklearn.svm.OneClassSVM — scikit-learn 0.24.1 documentation
scikit-learn.org
PS. SVM(Support Vector Machine)이란?
출처 : hleecaster.com/ml-svm-concept/
서포트 벡터 머신(Support Vector Machine) 쉽게 이해하기 - 아무튼 워라밸
서포트 벡터 머신은 분류 과제에 사용할 수 있는 강력한 머신러닝 지도학습 모델이다. 일단 이 SVM의 개념만 최대한 쉽게 설명해본다. 결정 경계, 하드 마진과 소프트 마진, 커널, C, 감마 등의 개
hleecaster.com
피어슨상관
카이제곱검정
제로분산
분산 인플레이션 계수
ANN
Decison tree C5.0
LSVM
KNN
'정리필요 > 논문리뷰' 카테고리의 다른 글
| [논문리뷰] 초진환자 재방문 예측모형 개발 (0) | 2021.03.29 |
|---|---|
| [논문리뷰] 유방암 분류를위한 적층 앙상블 기법 (0) | 2021.03.25 |
| [논문리뷰] 응급실 환자의 한국인 분류 및 시력 척도 수준의 머신 러닝 기반 예측 (0) | 2021.03.23 |
| [논문리뷰] 건강검진정보(2009-2016) 자료를 이용한 신체 정보와 이상지질혈증 지표의 정준상관 연구 (0) | 2021.03.22 |
| [논문리뷰]SCIBERT: A Pretrained Language Model for Scientific Text (1) | 2021.03.15 |