https://www.mdpi.com/2078-2489/10/4/150
Text Classification Algorithms: A Survey
In recent years, there has been an exponential growth in the number of complex documents and texts that require a deeper understanding of machine learning methods to be able to accurately classify texts in many applications. Many machine learning approache
www.mdpi.com
논문지 : MDPI Information Vol.10, No.4 (Citescore 4.2,)
게재일 : 2019.4
저 자 : Kamran Kowsari, Kiana Jafari Meimandi, Mojtaba Heidarysafa, Sanjana Mendu, Laura Barnes, Donald Brown
1. Introduction
- 텍스트 분류 및 문서 분류 시스템은 특징 추출, 차원 축소, 분류 기 선택 및 평가의 단계로 나눌수 있음
- 텍스트 분류 시스템은 "문서 > 단락 > 문장 > 하위 문장(문장의 일부)" 수준으로 구분됨
- [step 1 특징추출] 불필요한 문자와 단어를 생략해야함, TF-IDF, TF, Word2Vec 및 Glove를 일반적으로 사용함
- [step 2 차원감소] PCA, LDA, NMF, 랜덤 프로젝션, 오토인코더, t-SNE 기술 등을 사용함
- [step 3 분류] Rocchio, 앙상블기법(boosting, bagging), 로지스틱 회귀, Naive Bayes Classifier, KNN, SVM,
Tree 기반 알고리즘(decision tree, Random forest), Conditional Random Fields, Deep learning
- [step 4 평가] Accuracy, F score, matthews correlation coefficient, ROC, AUC
2. 텍스트 전처리
- [전처리] 불용어, 철자 오류, 소거 등과 같은 불필ㅇ요한 데이터는 통계 및 확률 학습 알고리즘에서 노이즈 및 악영향을 미칠 수 있음
- [토큰화] 텍스트를 의미 있는 요소로 나누는 전처리 방법, 문장의 단어를 조사함
- [불용어] 텍스트 및 문서에서 중요한 의미를 포함하지 않는 단어를 처리하는 것
- [capitalization] 대문자 사용을 처리하는 가장 일반적인 방법은 모든 문자를 소문자로 줄이는 것이지만 US와 같이 속어 및
약어 변환기는 예외 설명이 필요
- [속어 및 약어]
- [노이즈 제거] 대부분 텍스트 데이터에는 구두점 및 특수 문자와 같은 불필요한 문자가 많이 포함됨
- [맞춤법 교정] Trie 및 Damerau-Levenshtein distance bigram을 사용한 철자 교정이나 해싱 기반 및 상황에 맞는 철자 교정 기술 연구가 많음
- [원형화, Lemmatization] 기본 단어 형태를 얻기 위해 단어의 접미사를 다른 것으로 바꾸거나 단어의 접미사를 제거함
2.1 단어 표현
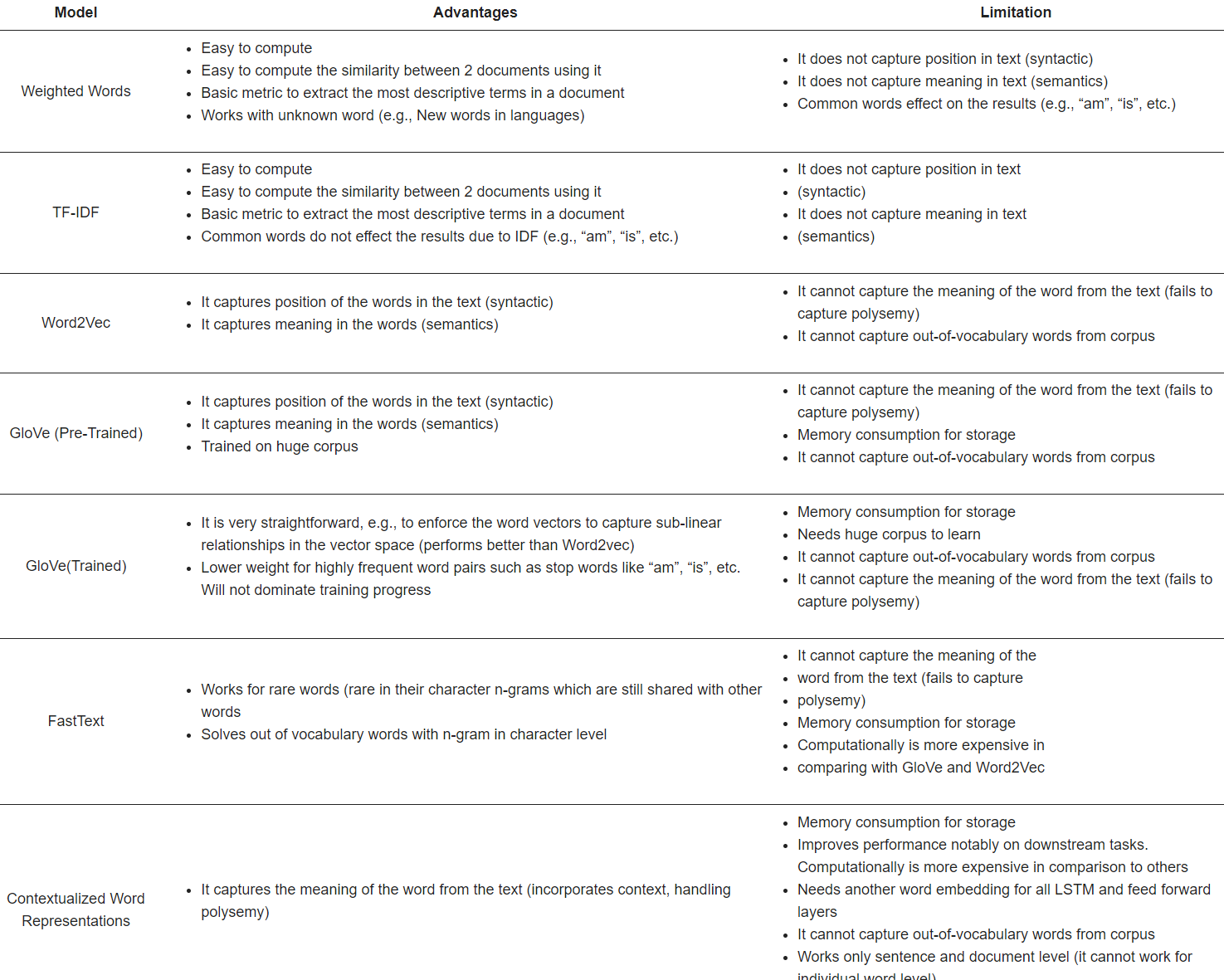
- N-gram :
- BoW : 문법과 출현 순서는 무시되지만 다중성은 계산됨. 단, 문법과 출현 순서를 고려하지 않음
- TF-IDF : 말뭉치에서 암묵적으로 공통된 단어의 영향을 줄이기 위해 용어 빈도와 함께 사용되는 방법.
단, 단어 간의 유사성을 설명할 수 없음
- Word2Vec : 두 개의 은닉층, CBOW(continuous bag-of-words) 및 Skip-gram 모델이 있는 얕은 신경망을 사용해 단어에 대한 고차원 벡터 생성
- GloVe : Wikipedia 2014 및 Gigaword 5를 통해 훈련된 400,000개의 어휘와 단어 표현을 위한 50개의 차원을 기반으로 함
Twitter 콘텐츠를 포함하여 더 큰 말뭉치에 대해 훈련된 100, 200, 300 차원의 사전 훈련된 단어 벡터화를 제공함
- FastText : 300 차원을 기반으로 Wikipedia에서 훈련된 294개 언어에 대한 사전 훈련된 단어 벡터를 게시함.
기본 매개변수와 Skip-gram 모델을 사용함.
2.2 차원 축소
- PCA, ICA, LDA, NMF, Random Kitchen Sinks, Johnson Lindenstrauss Lemma
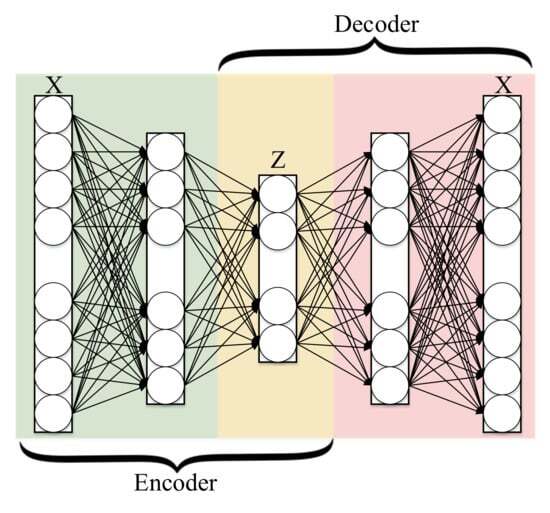
2.3 Autoencoder
- t-SNE : 고차원 데이터를 삽입하기 위한 비선형 차원 감소 방법
2.4 기본 분류 기법
- 로키오 분류는 몇 가지 관련 문서만 검색할 수 있음
- 부스팅과 배깅은 계산 복잡성 및 해석 가능성 손실과 같은 단점이 있음
- (다항) 로지스틱 회귀은 범주형 결과를 예측하는 데 적합하지만 각 데이터 포인트가 독립적이어야 하며, 독립 변수 집합을 기반으로 결과를 예측하려 시도함
- (다항) 나이브 베이지안은 불균형 클래스를 위한 방법을 적용하는 기법이 연구되기도 했지만 데이터 분포 모양에 대해 영향이 커서 희소한 데이터는 제한됨
- KNN은 가중치 조정 등 다양하게 연구되었지만 데이터 의존적인 알고리즘임
- SVM은 텍스트 분류를 위해 많은 수의 차원으로 인해 결과의 투명성이 부족하여 제한됨
- Decision Tree는 매우 빠른 알고리즘 이지만 데이터의 작은 변동에 극도로 민감하며, 쉽게 과적합될 수 있음
- Random Forest는 딥러닝과 같은 다른 기술과 비교하여 텍스트 데이터 세트에 대해 숲의 나무 수가 많을 수록 시간 복잡성이 증가함
- CRF는 높은 기능 공간으로 인해 텍스트 데이터에 대한 훈련 단계의 높은 계산 복잡성. 또한 훈련 데이터에 없는 단어에 대한 수행불가
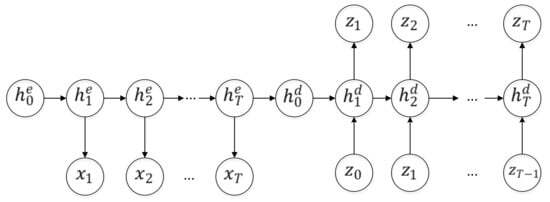
2.5 딥러닝
- DNN, RNN, LSTM, CNN, GRU(Gated Recurrent Unit), HAN(Hierarchical Attention Networks),
RMDL(Random multimodel deep learning))
- RMSprop : 편향 보정을 수행하지 않으므로 희소 기울기를 처리할 때 심각한 문제가 발생함
- Adam : RMSprop의 희소 기울기 문제 극복함
- Adagrad : 데이터의 기하학에 대한 지식을 동적으로 흡수하는 새로운 하위 기울기 방법론
- AdaDelta : 기하급수적으로 감소하는 평균을 사용함
-> 블랙박스 문제. 기존 기계 학습 알고리즘보다 훨씬 더 많은 데이터가 필요. 계산 복잡성 악화시킴
2.6 평가
- accuracy, sensitivity, specificity, precision, recall, F1-score, Micro Average, Macro Average, MCC, AUC,
ROC
3. 고찰
- 텍스트 분류는 정보 검색, 정보 필터링, 감정 분석, 추천 시스템, 지식 관리(데이터 관리), 문서 요약
- 건강(EHR 데이터가 개인화됨), 사회 과학, 비즈니스 및 마케팅, 법 등 분야에 사용됨
'AI > NLP' 카테고리의 다른 글
| [논문리뷰] Clinical text classification research trends: Systematic literature review and open issues (0) | 2023.04.18 |
|---|