
공부 기록
[논문리뷰] Clinical text classification research trends: Systematic literature review and open issues 본문
[논문리뷰] Clinical text classification research trends: Systematic literature review and open issues
kstar2 2023. 4. 18. 15:19https://www.sciencedirect.com/science/article/pii/S0957417418306110
Clinical text classification research trends: Systematic literature review and open issues
The pervasive use of electronic health databases has increased the accessibility of free-text clinical reports for supplementary use. Several text cla…
www.sciencedirect.com
논문정보
저널 : Expert Systems with Applicatinos vol 116 [SCIE IF 8.665]
게재 : 2019.2
저자 : Ghulam Mujtaba, Liyana Shuib, Norisma Idris, Wai Lam Hoo, Ram Gopal Raj, Kamran Khowaja, Khairunisa Shaikh, Henry Friday Nweke
1. Introduction
1.1 Free Text 형식의 EHR의 이점 및 분류 방법
- EHR에는 유익한 정보가 Free Text 형식으로 포함되며 2차 사용에 유익함
- 지도, 비지도, 반지도, 온톨로지 기반, 규칙기반, 전이학습, 강화 및 다중 보기 학습 기법으로 임상 보고서를 분류함
1.2 의료 영역에서 텍스트 분류의 어려움
1) [데이터 전처리 문제] 임상 보고서 말뭉치는 일반적으로 높은 수준의 잡음, 희소성, 복잡한 의학적 어휘, 의학적 척도 및 점수(ex. 혈압 140/65), 약어, 철자가 틀린 단어 및 빈약한 문법 문장이 포함됨
-> 사전 분석을 통해 언어적 특성을 밝혀야함
2) [클래스 불균형 문제] 클래스 분포가 불균형하여 질병을 보유한 임상 문서보다 정상인 클래스에 비해 부족한 문제가 발생함
-> 적은 클래스는 분류에서 무시되거나 이상치로 가정되어 더 많으 오분류를 유발할 수 있음
-> 진단 오류는 환자에게 스트레스와 추가 합병증을 유발할 수 있어 양성 클래스에서 높은 식별률을 달성할 수 있어야 함
3) [의미론적 정보 문제] 전문가가 다양한 의학적 단어나 구문을 상호 교환하여 사용할 수 있음
-> SNOMED-CT와 같은 전문화된 의학 온톨로지 기반 유사한 용어를 고유한 개념 ID로 변환하여 동의어 및 다의어 문제 극복하려함
1.3 연구 목적
2013년 1월부터 2018년 1월까지 발표된 임상 텍스트 분류에 관한 학술 논문을 평가
2. 주요 리뷰 내용
- EEG 신호와 같은 의료 분야에서는 텍스트 분류를 처리하는 것이 없음
2.1 임상 보고서 유형
- 기존 연구에서는 병리 보고서, 방사선 보고서, 부검 보고서, 사망 증명서, 생의학 문서 등 9가지 유형 임상 보고서가 사용됨
- 병리학 보고서, 생물 의학 문서, 방사선 보고서, 부검 보고서 순으로 텍스트 분류에 사용함
- 암 단계 감지, 암 탐지(비사전 기반 및 사전 기반 분류), 사지 골절 식별, 뇌손상 식별하기 위한 CT 보고서과 관련된 보고서 등 다야하게 진행됨
2.2 데이터 세트 및 특성 검토
1) 한 가지 유형의 임상 보고서로 구성되어 하나의 데이터 소스 또는 병원에서 수집됨
2) 한 가지 유형의 임상 보고서로 구성되며 서로 다른 데이터 소스 또는 병원에서 수집됨
3) 다양한 유형의 임상 보고서로 구성되며 일반적으로 하나의 데이터 소스 또는 하나의 병원에서 수집됨
4) 다양한 유형의 임상 보고서로 구성되며 다른 데이터 소스 또는 다른 병원에서 수집됨
2.3 전처리 및 샘플링 기술
<전처리>
1) [전처리 기법] 불용어 제거, 구두점이나 특수기호 제거, 빈칸 제거, 대소문자 변환, 철자 교정, 토큰화, 형태소 분석, 표준어 추출, 정규화 등 전처리 기법 적용
2) [불용어에 대한 처리] 소수의 연구에서는 불용어의 유무를 실증적으로 조사하여 불용어의 존재가 부재보다 더 나은 정확도를 생성한다고 보고함
3) [기본 전처리 + 단어 토큰화 + 형태소 분석] 일부 연구에서 분류 성능 향상됨을 입증함
4) stemming 및 표제어 추출 기술
5) 형태소 분석 및 원형 추출이 부적합한 경우도 있으며 숫자나 날짜를 같은 단위로 변환하는 기술은 거의 적용하지 않음
<샘플링> -> 불균형 문제 극복하기 위해
1) SMOTE - 1차 연구에서 사용되지 않았으므로 클래수 분포에 대한 SMOTE 기술의 효과를 테스트하기 위한 잠재적인 향후 작업이 될 수 있음
2) 무작위로 제거하거나, 언더 샘플링 기법 적용 -> 데이터 손실될 수 있지만 가장 성공적인 샘플링 방법 중 하나 임
2.4 feature engineering
1) feature extraction
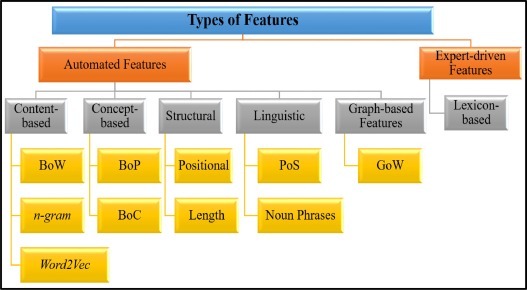
2) feature 표현 기법 : 이진 표현, 용어 빈도, TFiDF(역 문서 빈도가 있는 용어 빈도), N-TFiDF
3) feature selection : 정보 이득, 카이제곱, 피어슨 상관관계, 전문가 중심, Local Semi Supervised Feature selection,
상호정보, Gini-Index, Distinguishing Feature Selector, PCA, 다중 판별 분석(MDA),
Bi-Normal Separation Score
2.5 ML 기법
- Naive Bayes, Rule based, SVM, AdaBoost, ANN, k-NN, Decision Tree 등
2.6 평가
- Precision, Recall, F-measure, accuracy, ROC curve
3. 향후 연구 방향
- [데이터 세트의 품질] : 대부분 동종-균일 임상 보고서 사용함 -> 여러 병원에 일반화하는 데 장애 발생 가능
- [임상 텍스트 분류의 빅데이터] : 일반화를 위해 여러 기관에서 임상 보고서를 수집해야함
- [공개 사용가능한 데이터셋] : 표준 데이터 필요 ex. i2b2, OHSUMED, PhysioNet
- [feature 품질 및 동적 기능 세트 업데이트] : 콘텐츠 기반(BoW, n-gram), 개념적 기능(BoC), 전문가 기반에서 성능 향상이 나타남 -> 전체 모델을 다시 구축하지 않고도 기능을 점진적으로 추가하거나 제거할 수 있는 방법 설계해아함
- [딥러닝 연구 필요] 72개 중 3개만 딥러닝 사용함
- [비지도 클러스터링 기법]
- [반지도 학습 기법 적용]
- [그래프 기반 접근 방식 적용] 콘텐츠 기반 기능 한계를 극복하기 위해 GoW 기능을 사용함 -> 향후 연구에서는 GoW 기능 초점
- [온톨로지 활용] 온톨로지를 이용한 임상 보고서의 분류를 강조할 수 있음, 기존에는 주로 지도학습 기반 또는 규칙 기반이었음
- [다언어 연구] 대부분 영어 데이터로만 연구가 이뤄짐, 중국어 등으로 작성된 데이터에 대한 연구도 필요
- [강화학습 적용]
- [전이학습 적용] 학습된 지식을 사용하여 관련 또는 다른 도메인의 성능을 향상시킴, 교육시간 단축 등 용이함으로 전이학습 접근 방식이 바람직함
'예전 것들 > NLP' 카테고리의 다른 글
| [논문리뷰] Text Classification Algorithms: A Survey (0) | 2023.04.18 |
|---|
